Published Research
NLP and machine learning for predicting law-making
Nay, J. J. (2017). “Predicting and understanding law-making with word vectors and an ensemble model.” PLoS ONE 12(5): e0176999. https://doi.org/10.1371/journal.pone.0176999
Abstract
Out of nearly 70,000 bills introduced in the U.S. Congress from 2001 to 2015, only 2,513 were enacted. We developed a machine learning approach to forecasting the probability that any bill will become law. Starting in 2001 with the 107th Congress, we trained models on data from previous Congresses, predicted all bills in the current Congress, and repeated until the 113th Congress served as the test. For prediction we scored each sentence of a bill with a language model that embeds legislative vocabulary into a high-dimensional, semantic-laden vector space. This language representation enables our investigation into which words increase the probability of enactment for any topic. To test the relative importance of text and context, we compared the text model to a context-only model that uses variables such as whether the bill’s sponsor is in the majority party. To test the effect of changes to bills after their introduction on our ability to predict their final outcome, we compared using the bill text and meta-data available at the time of introduction with using the most recent data. At the time of introduction context-only predictions outperform text-only, and with the newest data text-only outperforms context-only. Combining text and context always performs best. We conducted a global sensitivity analysis on the combined model to determine important variables predicting enactment.
Neural network-based NLP method for modeling law and policy texts
Nay, J. J. (2016). “Gov2Vec: Learning Distributed Representations of Institutions and Their Legal Text.” Proceedings of the Empirical Methods in Natural Language Processing Workshop on NLP and Computational Social Science, 49–54, Association for Computational Linguistics.
Abstract
We embed institutions and their words into shared continuous vector space to enable novel investigations into law and policy differences across institutions. We apply this method, Gov2Vec, to Supreme Court opinions, Presidential actions, and official summaries of Congressional bills. The model discerns meaningful differences between government branches. We also learn representations for more fine-grained word sources: individual Presidents and Congresses. The similarities between learned representations of Congresses over time and sitting Presidents are negatively correlated with the bill veto rate, and the temporal ordering of Presidents and Congresses was implicitly learned from only text. With the resulting vectors we answer questions such as: how does Obama and the 113th House differ in addressing climate change and how does this vary from environmental or economic perspectives? Our work illustrates vector-arithmetic-based investigations of complex relationships between word sources. We are extending this to create a comprehensive legal semantic map.
A review of NLP and machine learning methods for legal informatics
Nay, J. J. (2017, Forthcoming). “Natural Language Processing and Machine Learning for Legal Text.” In D. M. Katz, R. Dolin & M. Bommarito (Eds.), Legal Informatics. Cambridge University Press.
Predicting human cooperation with machine learning methods
- Nay, J. J., Vorobeychik, Y. (2016). “Predicting Human Cooperation” PLoS ONE 11(5): e0155656.
Abstract
The Prisoner’s Dilemma has been a subject of extensive research due to its importance in understanding the ever-present tension between individual self-interest and social benefit. A strictly dominant strategy in a Prisoner’s Dilemma (defection), when played by both players, is mutually harmful. Repetition of the Prisoner’s Dilemma can give rise to cooperation as an equilibrium, but defection is as well, and this ambiguity is difficult to resolve. The numerous behavioral experiments investigating the Prisoner’s Dilemma highlight that players often cooperate, but the level of cooperation varies significantly with the specifics of the experimental predicament. We present the first computational model of human behavior in repeated Prisoner’s Dilemma games that unifies the diversity of experimental observations in a systematic and quantitatively reliable manner. Our model relies on data we integrated from many experiments, comprising 168,386 individual decisions. The model is composed of two pieces: the first predicts the first-period action using solely the structural game parameters, while the second predicts dynamic actions using both game parameters and history of play. Our model is successful not merely at fitting the data, but in predicting behavior at multiple scales in experimental designs not used for calibration, using only information about the game structure. We demonstrate the power of our approach through a simulation analysis revealing how to best promote human cooperation.
A machine learing method and software for estimating models of dynamic decision-making that both have strong predictive power and are interpretable in human terms
- Software package website: datafsm.
- Software package on CRAN.
- Nay, J. J., Gilligan, J. (2015). “Data-Driven Dynamic Decision Models”. Proceedings of the 2015 Winter Simulation Conference. 2752-2763, IEEE Press.
- Article available here: Data-Driven Dynamic Decision Models.
Abstract
This article outlines a method for automatically generating models of dynamic decision-making that both have strong predictive power and are interpretable in human terms. This is useful for designing empirically grounded agent-based simulations and for gaining direct insight into observed dynamic processes. We use an efficient model representation and a genetic algorithm-based estimation process to generate simple approximations that explain most of the structure of complex stochastic processes. This method, implemented in C++ and R, scales well to large data sets. We apply our methods to empirical data from human subjects game experiments and international relations. We also demonstrate the method’s ability to recover known data-generating processes by simulating data with agent-based models and correctly deriving the underlying decision models for multiple agent models and degrees of stochasticity.

A computer simulation model of prediction markets
- Nay, J. J., Van der Linden, M., Gilligan, J. (2016, Forthcoming) “Betting and Belief: Prediction Markets and Attribution of Climate Change.” Proceedings of the 2016 Winter Simulation Conference. IEEE Press.
Abstract
Despite much scientific evidence, a large fraction of the American public doubts that greenhouse gases are causing global warming. We present a simulation model as a computational test-bed for climate prediction markets. Traders adapt their beliefs about future temperatures based on the profits of other traders in their social network. We simulate two alternative climate futures, in which global temperatures are primarily driven either by carbon dioxide or by solar irradiance. These represent, respectively, the scientific consensus and a hypothesis advanced by prominent skeptics. We conduct sensitivity analyses to determine how a variety of factors describing both the market and the physical climate may affect traders' beliefs about the cause of global climate change. Market participation causes most traders to converge quickly toward believing the "true" climate model, suggesting that a climate market could be useful for building public consensus.
A machine learning approach to modeling dynamic decision-making in strategic interactions and prediction markets (PhD Dissertation)
- Nay, J. J. (2017). “A Machine Learning Approach to Modeling Dynamic Decision-Making in Strategic Interactions and Prediction Markets.” Vanderbilt University.
A machine learning software system for global prediction of remotely sensed vegetation health
- Nay, J. J., Burchfield, E., Gilligan, J. (2016). “A Machine Learning Approach to Forecasting Remotely Sensed Vegetation Health” eprint arXiv:1602.06335. [Under Review].
- Burchfield, E., Nay, J. J., Gilligan, J. (2016). “Application of Machine Learning to the Prediction of Vegetation Health” ISPRS-International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, XLI-B2, 465-469.
Abstract
This project applies machine learning techniques to remotely sensed imagery to train and validate predictive models of vegetation health in Bangladesh and Sri Lanka. For both locations, we downloaded and processed eleven years of imagery from multiple MODIS datasets which were combined and transformed into two-dimensional matrices. We applied a gradient boosted machines model to the lagged dataset values to forecast future values of the Enhanced Vegetation Index (EVI). The predictive power of raw spectral data MODIS products were compared across time periods and land use categories. Our models have significantly more predictive power on held-out datasets than a baseline. Though the tool was built to increase capacity to monitor vegetation health in data scarce regions like South Asia, users may include ancillary spatiotemporal datasets relevant to their region of interest to increase predictive power and to facilitate interpretation of model results. The tool can automatically update predictions as new MODIS data is made available by NASA. The tool is particularly well-suited for decision makers interested in understanding and predicting vegetation health dynamics in countries in which environmental data is scarce and cloud cover is a significant concern.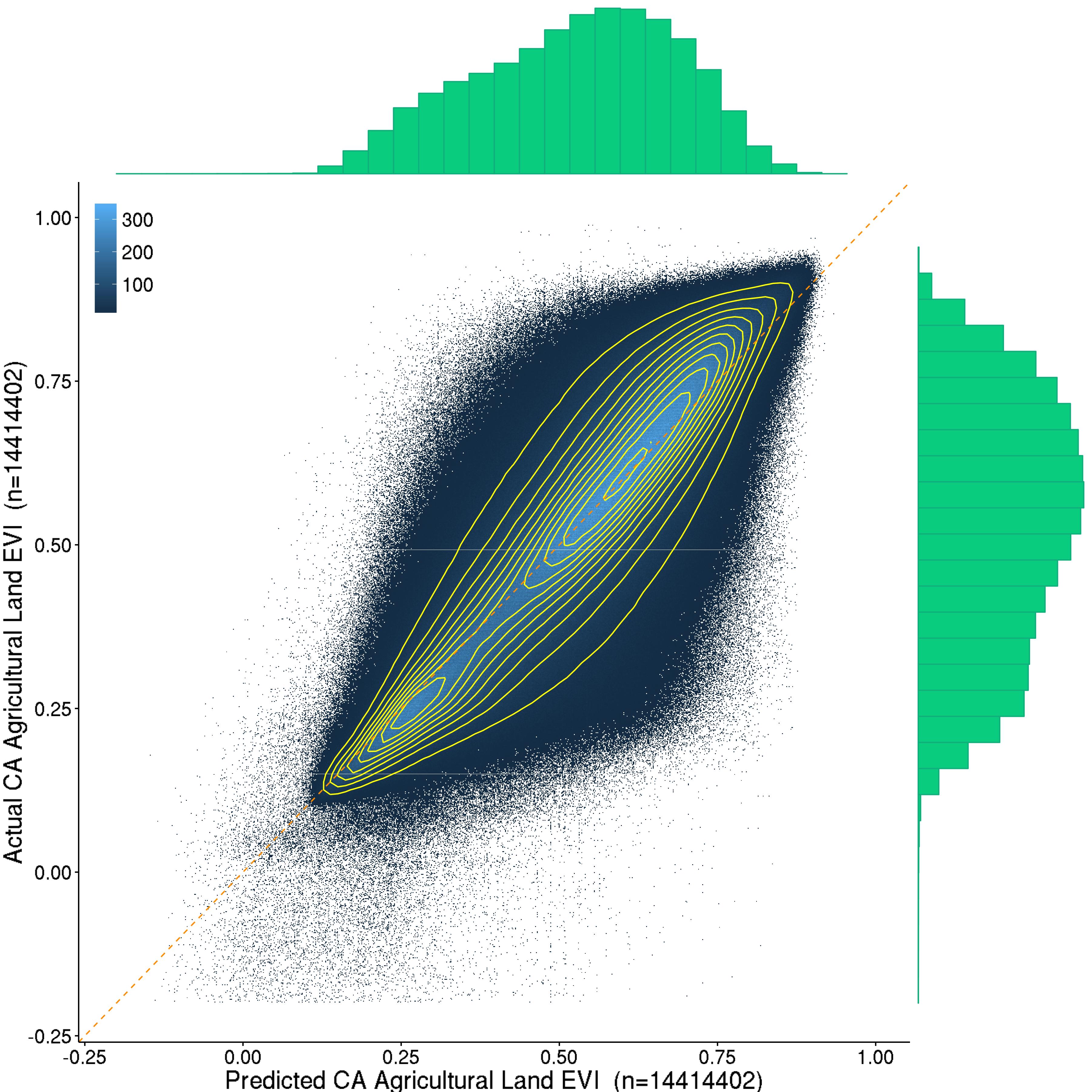
Building and testing a participatory computer simulation tool for learning and decision-support for flood risk management
- Code available here
- Gilligan, J. M., Brady, C., Camp, J., Nay, J. J., Sengupta, P. (2015). “Participatory Simulation of Urban Flooding for Learning and Decision Support” In L. Yilmaz, W. K. V. Chan, I. Moon, T. M. K. Roeder, C. M. Macal, M. Rosetti (Eds.), Proceedings of the 2015 Winter Simulation Conference. 3174-3175. IEEE Press.
Abstract
Flood-control measures, such as levees and floodwalls, can backfire and increase risks of disastrous floods by giving the public a false sense of security and thus encouraging people to build valuable property in high-risk locations. More generally, nonlinear interactions between human land-use and natural processes can produce unexpected emergent phenomena in coupled human-natural systems (CHNS). We describe a participatory agent-based simulation of coupled urban development and flood risks and discuss the potential of this simulation to help educate a wide range of the public---from middle- and high-school students to public officials---about emergence in CHNS and present results from two pilot studies.
A computer simulation of the impact of forecast use on agricultural income
Gunda, T., Bazuin, J., Nay, J., Yeung, K. (2017). “Impact of seasonal forecast use on agricultural income in a system with varying crop costs and returns: an empirically-grounded simulation”. Environmental Research Letters, DOI: 10.1088/1748-9326/aa5ef7. Model available online at OpenABM.
Abstract
Access to seasonal climate forecasts can benefit farmers by allowing them to make more informed decisions about their farming practices. However, it is unclear whether farmers realize these benefits when crop choices available to farmers have different and variable costs and returns; multiple countries have programs that incentivize production of certain crops while other crops are subject to market fluctuations. We hypothesize that the benefits of forecasts on farmer livelihoods will be moderated by the combined impact of differing crop economics and changing climate. Drawing upon methods and insights from both physical and social sciences, we develop a model of farmer decision-making to evaluate this hypothesis. The model dynamics are explored using empirical data from Sri Lanka; primary sources include survey and interview information as well as game-based experiments conducted with farmers in the field. Our simulations show that a farmer using seasonal forecasts has more diversified crop selections, which drive increases in average agricultural income. Increases in income are particularly notable under a drier climate scenario, when a farmer using seasonal forecasts is more likely to plant onions, a crop with higher possible returns. Our results indicate that, when water resources are scarce (i.e. drier climate scenario), farmer incomes could become stratified, potentially compounding existing disparities in farmers' financial and technical abilities to use forecasts to inform their crop selections. This analysis highlights that while programs that promote production of certain crops may ensure food security in the short-term, the long-term implications of these dynamics need careful evaluation.A review of decision-support computational modeling approaches to informing climate change adaptation policy
- Nay, J. J., Abkowitz, M., Chu, E., Gallagher, D., Wright, H. (2014). “A Review of Decision-Support Models for Adaptation to Climate Change in the Context of Development”. Climate and Development, 6:4, 357-367.
Abstract
In order to increase adaptive capacity and empower people to cope with their changing environment, it is imperative to develop decision-support tools that help people understand and respond to challenges and opportunities. Some such tools have emerged in response to social and economic shifts in light of anticipated climatic change. Climate change will play out at the local level, and adaptive behaviours will be influenced by local resources and knowledge. Community-based insights are essential building blocks for effective planning. However, in order to mainstream and scale up adaptation, it is useful to have mechanisms for evaluating the benefits and costs of candidate adaptation strategies. This article reviews relevant literature and presents an argument in favour of using various modelling tools directed at these considerations. The authors also provide evidence for the balancing of qualitative and quantitative elements in assessments of programme proposals considered for financing through mechanisms that have the potential to scale up effective adaptation, such as the Adaptation Fund under the Kyoto Protocol. The article concludes that it is important that researchers and practitioners maintain flexibility in their analyses, so that they are themselves adaptable, to allow communities to best manage the emerging challenges of climate change and the long-standing challenges of development.
A comparison of machine learning models for predicting individual-level cooperation behavior
- Nay, J. J. (2014). “Predicting Cooperation and Designing Institutions: An Integration of Behavioral Data, Machine Learning, and Simulation” In A. Tolk, S. Y. Diallo, I. O. Ryzhov, L. Yilmaz, S. Buckley, J. A. Miller (Eds.), Proceedings of the 2014 Winter Simulation Conference. 4041-4042. IEEE Press.
Abstract
Empirical game theory experiments attempt to estimate causal effects of institutional factors on behavioral outcomes by systematically varying the rules of the game with human participants motivated by financial incentives. I developed a computational simulation analog of empirical game experiments that facilitates investigating institutional design questions. Given the full control the artificial laboratory affords, simulated experiments can more reliably implement experimental designs. I compiled a large database of decisions from a variety of repeated social dilemma experiments, developed a statistical model that predicted individual-level decisions in a held-out test dataset with 90% accuracy, and implemented the model in agent-based simulations where I apply constrained optimization techniques to designing games – and by theoretical extension, institutions – that maximize cooperation levels. This presentation describes the methodology, preliminary findings, and future applications to applied simulation models as part of ongoing multi-disciplinary projects studying decision-making under social and environmental uncertainty.
Modeling water conservation policy and related variables for U.S. cities to understand conditions that facilitate water conservation policy adoption
- Hess, D., Wold, C., Hunter, E., Nay, J.J., Worland, S., Gilligan, J., Hornberger, G. (2016). “Drought, Risk, and Institutional Politics in the American Southwest.” Sociological Forum, 1573-7861.
Abstract
Although there are multiple causes of the water scarcity crisis in the American Southwest, it can be used as a model of the long-term problem of freshwater shortages that climate change will exacerbate. We examine the water-supply crisis for 22 cities in the extended Southwest of the United States and develop a unique, new measure of water conservation policies and programs. Convergent qualitative and quantitative analyses suggest that political conflicts play an important role in the transition of water-supply regimes toward higher levels of demand-reduction policies and programs. Qualitative analysis using institutional theory identifies the interaction of four types of motivating logics—development, rural preservation, environmental, and urban consumer—and shows how demand-reduction strategies can potentially satisfy all four. Quantitative analysis of the explanatory factors for the variation in the adoption of demand-reduction policies points to the overwhelming importance of political preferences as defined by Cook's Partisan Voting Index. We suggest that approaches to water-supply choices are influenced less by direct partisan disagreements than by broad preferences for a development logic based on supply-increase strategies and discomfort with demand-reduction strategies that clash with conservative beliefs.
Software packages that facilitate data-driven simulation modeling and simulation analysis. Parameter estimation, sensitivity analyses, and visualization
- Software package website: sa.
- Software package website: eat: Empirical Agent Training.
- Software package website: agp: Agent Gentic Programming Software for Data-Driven Modeling.
